 掃一掃
掃一掃大規(guī)模人臉圖像編輯理論、方法及應(yīng)用
來源:未知 時間:2021-18-16 瀏覽次數(shù):299次
生物特征識別(BIOMETRICS)技術(shù),是指通過計算機(jī)利用人體所固有的生理特征(指紋、虹膜、面相、DNA等)或行為特征(步態(tài)、擊鍵習(xí)慣等)來進(jìn)行個人身份鑒定的技術(shù)。本文主要介紹圖像編輯涉及的理論基礎(chǔ)和它的方法和應(yīng)用
一、基礎(chǔ)理論
1、全光人臉分析
在計算機(jī)處理圖像的過程中,涉及一個基本的概念就是全光函數(shù)。它是決定空間中光線呈現(xiàn)形式的因素組成的一個函數(shù),包括光譜信息、時間信息、空間信息、深度信息、亮度信息和方向信息等。如果波長固定,那就是灰度圖像,如果有多個波長,那就是彩色圖像;如果是時間有變化那么就是視頻;空間信息自然不用說了;如果考慮深度信息就是深度成像,在成像時會測量圖像的深度信息;如果考慮亮度信息就是高動態(tài)圖像;如果考慮光線方向,就是光場相機(jī)。所有這些組成了全光函數(shù),在人臉識別中我們需要對這個函數(shù)有所了解,從而得到比較符合真實世界的圖像。目前,我們智能感知與計算研究中心依托國家自然科學(xué)基金委重大儀器專項[1]和華為公司合作項目[4][5],已設(shè)計和搭建全光人臉采集系統(tǒng)和深度數(shù)碼變焦圖像分析設(shè)備。這部分工作主要由中心的張堃博和胡坦浩完成。

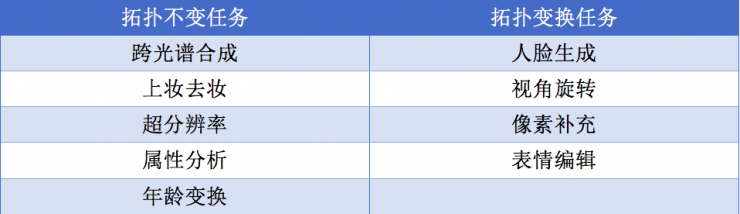
2、視覺拓?fù)鋬?yōu)先
圖像編輯的基本研究目標(biāo)是希望生成/合成的圖像是符合人的視覺認(rèn)知的,通俗而言就是讓觀察者判斷不出這個圖像是真實的還是計算機(jī)生成的。基于這些考慮,中科院的陳霖院士提出了視覺拓?fù)鋬?yōu)先的概念,他認(rèn)為人在識別人臉時對拓?fù)湫畔⒌淖兓母兄獌?yōu)先于其它信息。實際上,對于拓?fù)浣Y(jié)構(gòu)變化的敏感性是生物感知系統(tǒng)中的基本特性,例如蜜蜂對空心圓和實心圓的拓?fù)浣Y(jié)構(gòu)變化非常敏感。相關(guān)成果發(fā)表在《科學(xué)》雜志上。視覺拓?fù)鋬?yōu)先機(jī)制的數(shù)學(xué)建模問題一直是一個困難問題,我們中心在國家自然基金委重點(diǎn)基金項目[3]的支持下,深入研究了視覺拓?fù)鋬?yōu)先的多種數(shù)學(xué)表達(dá)形式,例如全局和局部結(jié)構(gòu)、小波分解、heatmap和人臉解析圖等。根據(jù)拓?fù)渥儞Q的性質(zhì),相關(guān)的人臉圖像編輯任務(wù)可以分為拓?fù)洳蛔內(nèi)蝿?wù)和拓?fù)渥儞Q任務(wù)。
3、生成對抗結(jié)構(gòu)
這里涉及到最常用的模型是生成模型,即學(xué)習(xí)聯(lián)合概率密度分布,它可以從統(tǒng)計的角度表示數(shù)據(jù)的分布情況,能夠反映同類數(shù)據(jù)本身的相似度。生成模型的主要功能有兩個:一是進(jìn)行密度估計,二是生成樣本。生成/合成人臉時,所要的就是生成/合成的人臉和真實人臉相似。生成模型中大家比較熟悉的就是GAN,即生成對抗網(wǎng)絡(luò)。大家都比較熟悉,我在這里就不再詳細(xì)介紹了。此外,我們也結(jié)合變分自編碼機(jī)和膠囊模型來研究新的生成式模型。
4、身份保持結(jié)構(gòu)
每個人都有自己的身份信息。人臉生成/合成任務(wù)自然希望能夠保持這個身份信息。在身份保持方面,我們的研究借鑒視覺認(rèn)知中最基本的概念,即,定序測量(Ordinal Measures,OM)。這是一個基本的度量方式。人類所采用的度量方式主要包含以下四種。

生活中,定序測量的思想隨處可見。比如我們只需要知道籃球比足球重,至于重多少克則大多數(shù)情況下是沒有必要知道的。根據(jù) OM 概念,中科院的譚鐵牛院士提出一個既簡單又好用的方法,即,通過簡單的比較大小,實現(xiàn)計算機(jī)視覺的復(fù)雜特征提取。最初這個研究工作應(yīng)用到虹膜識別,判斷虹膜是否屬于同一個人。基本思路就是通過比較大小得到一個特征編碼,通過這個特征編碼便可以進(jìn)行分類。目前這種思想已經(jīng)被廣泛應(yīng)用于計算機(jī)視覺中。
我們把這種定序測量的方式引入到卷積神經(jīng)網(wǎng)絡(luò)的激活函數(shù)中。常用的激活函數(shù)有兩種:ReLU 和Maxout。通常認(rèn)為,由于 Maxout 需要使用兩條直線才能近似 ReLU,因此,Maxout 網(wǎng)絡(luò)通常是 ReLU 網(wǎng)絡(luò)大小的兩倍以上。而我們這個方法采用的定序測量非常簡單,就是比數(shù)值大小,誰的值小誰就被抑制掉,因此可以得到一個比較小的卷積神經(jīng)網(wǎng)絡(luò)。

不同于以前的方法,我們借鑒神經(jīng)學(xué)中一個基本的概念:側(cè)向抑制。這是神經(jīng)元的激活機(jī)制,即通過對比機(jī)制來減少臨近神經(jīng)元的激活,同時神經(jīng)元能夠抑制一些神經(jīng)信號傳播,這種方式能夠增加神經(jīng)信號的清晰度。借用這種概念,我們在網(wǎng)絡(luò)中添加了側(cè)向抑制的機(jī)制,以眉毛區(qū)域為例,其相鄰水平位置激活,相鄰豎直位置就會被抑制。引入上述概念后,依托于國家自然科學(xué)基金委重點(diǎn)項目[2],我們中心的吳翔等設(shè)計了一個輕量級的神經(jīng)網(wǎng)絡(luò) Light CNN [6],該網(wǎng)絡(luò)具有提煉度高,空間占用小的特點(diǎn)。它在人臉識別以及車輛識別問題上都已經(jīng)取得了較好的效果。這個網(wǎng)絡(luò)所具有的結(jié)構(gòu)小而分辨率高的特點(diǎn)能夠輔助我們在人臉圖像編輯過程中進(jìn)行身份判別。該工作發(fā)表在上。目前,該研究工作受到國內(nèi)外研究者的較大關(guān)注,相關(guān)代碼已經(jīng)在 github 上公布,依據(jù)網(wǎng)絡(luò)層數(shù)不同,分為 LightCNN9 和 LightCNN29 兩個版本。
以上四個部分就是我們在研究人臉圖像的過程中遇到的基礎(chǔ)問題。首先,需要對光的結(jié)構(gòu)比較了解,只有了解了光的信息才有比較好的成像效果;其次,因為圖像是給人看的,因此生成的圖像要符合人的認(rèn)知;另外,介紹了一種基本的網(wǎng)絡(luò)結(jié)構(gòu),即生成對抗網(wǎng)絡(luò),來指導(dǎo)人臉圖像的編輯;最后是身份保持損失,目的是希望合成后的人臉圖像保持原有的身份信息。這四個部分構(gòu)成了圖像編輯的主要基礎(chǔ)部分,當(dāng)然還有一些其它部分。
二、方法應(yīng)用
接下來介紹一下我們中心近期做的一些相關(guān)研究內(nèi)容,由于時間關(guān)系,主要包括七個主要部分。每個部分在計算機(jī)視覺中都是獨(dú)立的分支,在金融民生或公共安全領(lǐng)域也都有很重要的應(yīng)用。
1、超分辨率
第一個是圖像超分辨率,即在給定低分辨率(LR)輸入的情況下估計出高分辨率(HR)圖像的問題。例如攝像頭采集的圖像一般分辨率比較低,如何對它進(jìn)行超分,得到一張清晰的圖像并保持其身份信息,就是我們所研究的內(nèi)容。

超分算法一般可以分為兩大類,一類屬于通用的超分算法,例如基于插值的方法、基于圖像統(tǒng)計的方法或者基于字典學(xué)習(xí)等的方法,這類算法適用于所有的圖像超分問題。另一類屬于特定領(lǐng)域的超分算法,例如基于先驗統(tǒng)計的方法,現(xiàn)在也有基于生成模型的方法以及感知損失函數(shù)的方法。


我們中心的黃懷波等提出在超分的過程中使用小波分解技術(shù)[13]。假設(shè)超分圖像的每個位置在超分時都依賴于原始的圖像對應(yīng)的地方,這樣我們的超分算法不會破壞全局信息。通常,超分問題被建模為一個概率問題。在這種模型中,給定輸入的圖像,直接預(yù)測完整的圖像,這個預(yù)測過程不能保證是不變的。不同于此,我們在訓(xùn)練時輸入一張高清的圖像,然后進(jìn)行小波分解,對分解后的圖像分別預(yù)測,之后再合成完整高清圖像,這樣得到的結(jié)果就可以盡量避免出現(xiàn)偏差。
2、視角旋轉(zhuǎn)
另外一個比較重要、也是現(xiàn)在各大公司比較關(guān)注的人臉視角旋轉(zhuǎn)應(yīng)用,即將歸一化的人臉旋轉(zhuǎn)到任意姿態(tài)。例如從一張正臉圖像生成側(cè)臉圖像;或反之,從采集到的一張側(cè)臉恢復(fù)其正臉圖像,公安領(lǐng)域常有此需求。
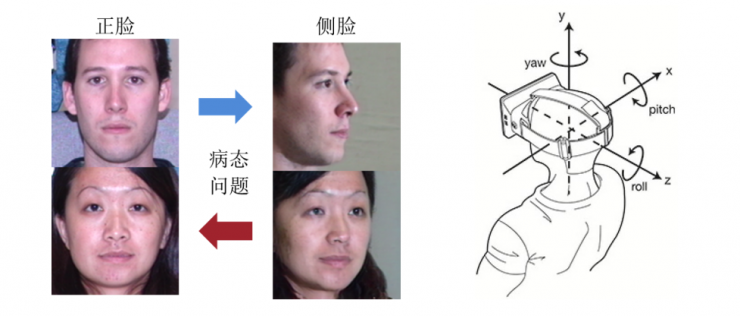
視角旋轉(zhuǎn)有 x、y、z 三個方向,我們目前只考慮左右偏轉(zhuǎn)。如果從單張圖像進(jìn)行旋轉(zhuǎn)的話,這需要「無中生有」,因為有些信息是沒有的,所以旋轉(zhuǎn)時結(jié)果存在偏差。人臉旋轉(zhuǎn)有兩部分研究內(nèi)容,一部分是 2D 模型,一部分是 3D 模型。
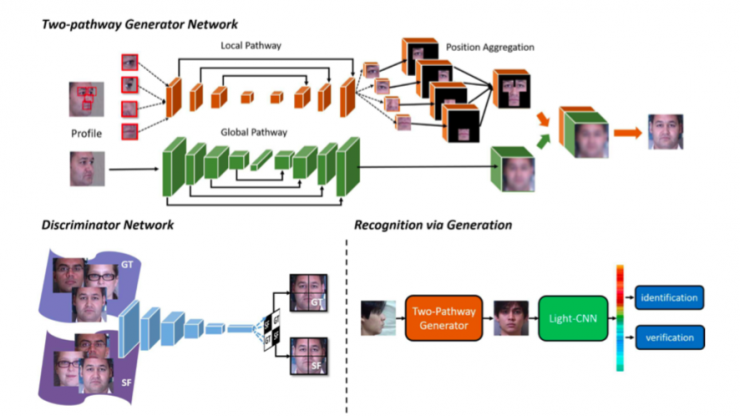
既然圖像合成比較難,又不能直接預(yù)測,因此,我們引入幾個局部通路專門負(fù)責(zé)人臉局部信息的合成,該工作發(fā)表在 ICCV 2017 [15]。根據(jù)人臉五官,我們引入四個局部通路,再加上一個全局的通路,同時保持全局和局部的拓?fù)浔3植蛔儭>植克膫€部分進(jìn)行分別合成,最后再與全局進(jìn)行融合,得到一個正臉。我們中心在該問題上的后續(xù)工作成果[9]發(fā)表在 CVPR2018 上。

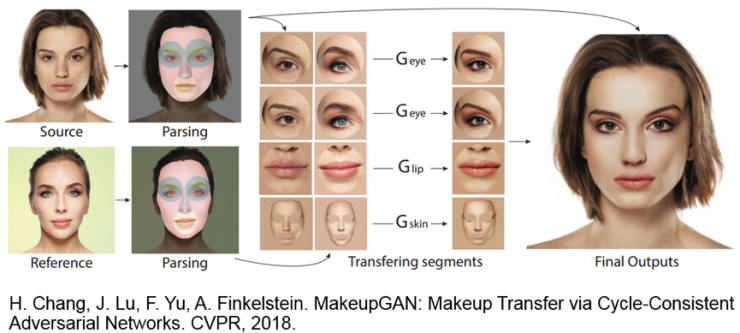
3、上妝去妝
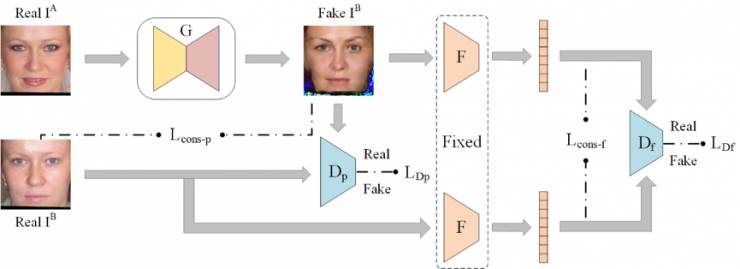
另外一個做的比較多的就是上妝去妝。「上妝」自然是希望在拍攝后把人臉進(jìn)行妝顏美化,去妝則是去除掉圖像中的妝容從而變?yōu)樗仡仭?/span>作為一個單獨(dú)的研究問題,上妝去妝從 2009 年開始陸續(xù)得到研究者的關(guān)注。2018 年,我們中心的李祎等提出利用生成網(wǎng)絡(luò)來完成去妝[11],并在 AAAI2018 上發(fā)表。我們主要希望針對手機(jī)用戶,使得去妝之后能夠得到比較好的視覺結(jié)果。跟前面的方法類似,這里仍需要保持拓?fù)浣Y(jié)構(gòu),同時我們提出兩層對抗網(wǎng)絡(luò),采用兩個判別器,一個是進(jìn)行身份信息判別,另外一個對是否為真實圖像進(jìn)行判別。
最新的自動上妝工作是2018年美國 Adobe 公司提出的模型。該方法以 cycleGAN 模型為基礎(chǔ),對眼部、唇部和其他面部皮膚分別上妝,之后再把分塊上妝結(jié)果反貼回原臉。由于該方法在合成全臉化妝效果時使用的是 image warping 方法,因此該方法實際上采用的是一種半生成模型。
4、表情編輯
表情編輯涉及到兩個問題,一個是表情合成,一個是表情去除。2018 年,我們中心的宋凌霄等提出一個新的表情合成/去除的算法[14],包括一下幾個基本部分:一、拓?fù)浣Y(jié)構(gòu)變化,因為眨眼的時候拓?fù)浣Y(jié)構(gòu)發(fā)生變化,因此希望用這個信息指導(dǎo)表情的變化;二、身份保持,我們不希望添加了表情后變成了另外一個人。我們的工作有兩個特點(diǎn),一個特點(diǎn)是能夠得到一個真實圖像,另外一個是能夠識別身份信息。

下面是我們方法得到的合成效果。

5、年齡變換
從娛樂領(lǐng)域而言,預(yù)測臉部年齡的變化是一個重要的應(yīng)用,其基本任務(wù)就是如何使人臉圖像老化/年輕化。
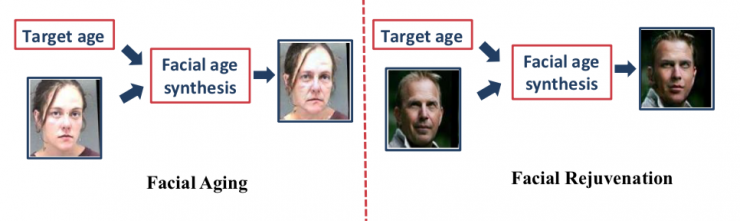
年齡變換在電影中應(yīng)用比較廣泛,例如年輕的演員在電影中變老,或年老的演員需要扮演年輕人等。在公安領(lǐng)域也有應(yīng)用,比如尋找丟失多年的兒童;當(dāng)然在隱私防范或生活娛樂中也有很多應(yīng)用。
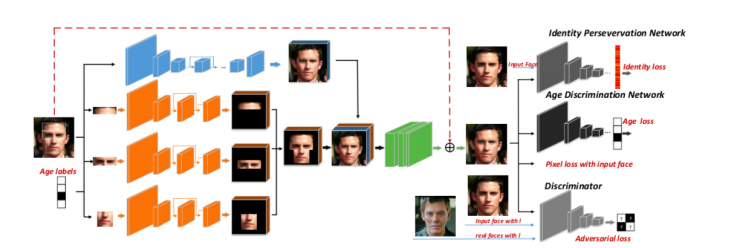
年齡合成作為計算機(jī)視覺的一個分支問題,其研究始于 1994 年。我們中心的李佩佩等在 2018 年提出了一種基于全局和局部的生成方法[12]。做年齡合成時,我們知道一般額頭、眼睛以及嘴角變化比較大。因此除了做一個全局通道外,我們還在模型匯總另外添加了三個局部通道,隨后將這三個局部通道合起來后再與全局通道融合在一起。同時,我們也使用多個判別器來保證合成結(jié)果的視覺效果。這是我們得到的實驗結(jié)果:

6、像素補(bǔ)充
接下來的工作是人臉補(bǔ)充,即把遮擋了的人臉補(bǔ)全,這在圖像編輯中也有很重要作用。現(xiàn)有方法可以歸納為三類:早期是使用基于補(bǔ)丁的方法,即通過觀察缺失內(nèi)容的上下文信息,從相同圖像或外部圖像數(shù)據(jù)庫中搜索相似的補(bǔ)丁;其次是基于擴(kuò)散方程的方法,即利用擴(kuò)散方程迭代地沿著邊界將低級特征從上下文區(qū)域傳播到缺失區(qū)域;第三種則是基于稀疏表示的方法,即如果缺了某塊兒區(qū)域,便通過編碼或者解碼,把原始的圖像補(bǔ)充上去[8]。2017 年,國外學(xué)者進(jìn)一步研究了基于生成模型的人臉補(bǔ)充,其目的是希望生成的拓?fù)浣Y(jié)構(gòu)和真實的拓?fù)浣Y(jié)構(gòu)保持一致。

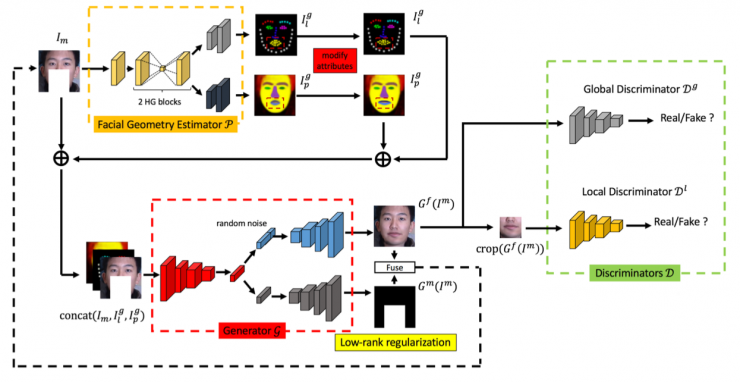
在圖像感知的時候,拓?fù)浣Y(jié)構(gòu)先于其它結(jié)構(gòu),所以我們考慮把拓?fù)浣Y(jié)構(gòu)作為先驗條件。基于這種考慮,我們中心的宋林森等提出一種新的方法(Geometry-Aware Face Completion and Editing),先預(yù)測缺失的地方,隨后再把這個拓?fù)浣Y(jié)構(gòu)跟原圖一起輸入,來生成真實的圖像。
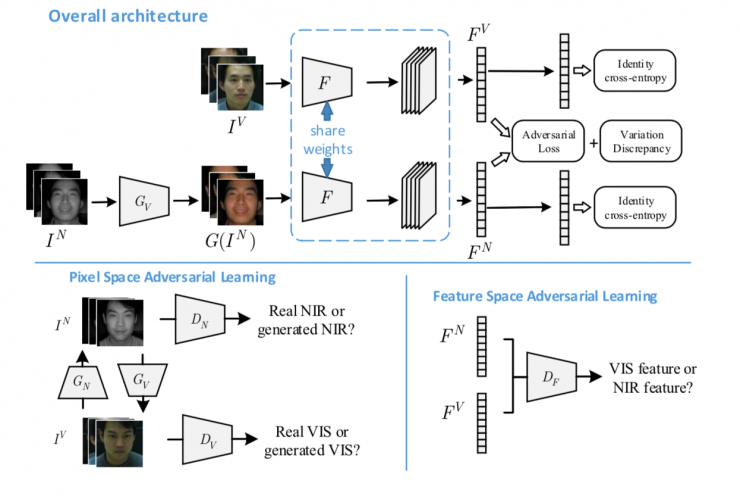
7、跨光譜合成
所謂跨光譜合成,指根據(jù)某種光譜/模態(tài)下的人臉圖像,直接合成其他光譜/模態(tài)人臉 圖像的技術(shù)。這個技術(shù)廣泛應(yīng)用于異質(zhì)人臉識別,例如下圖的可見光圖像和近紅外圖像間的人臉識別。這個問題的挑戰(zhàn)和光線有關(guān),一方面不同的圖像之間光線差別比較大,而另一方面可用于跨光譜訓(xùn)練的圖像數(shù)據(jù)集也比較小。不過這個領(lǐng)域的研究也比較多,包括基于字典學(xué)習(xí)的方法、基于補(bǔ)丁映射的方法和基于生成模型的方法等。

我們的工作[10]是基于生成模型的方法,發(fā)表在 AAAI 2018 上,這應(yīng)該是第一篇使用GAN模型的跨光譜合成方法。我們構(gòu)建了生成對抗異質(zhì)人臉識別模型(AD-HFR),并使用了全局和局部的結(jié)構(gòu),除了對整個臉部進(jìn)行生成外,還對眼睛部分進(jìn)行了專門處理,并且包含了身份保持函數(shù)。
三、總結(jié)
本次報告主要介紹了人臉圖像編輯涉及的基礎(chǔ)理論和應(yīng)用方法。由于時間關(guān)系,基礎(chǔ)理論部分還有部分內(nèi)容沒有深入介紹;而在應(yīng)用部分,今天主要講了超分辨率等,但還有人臉生成等許多應(yīng)用沒有涉及。
事實上人臉圖像編輯,是計算機(jī)視覺中一個長期的研究目標(biāo),當(dāng)前仍有很多問題沒有解決。例如,當(dāng)前研究的人臉圖像分辨率大多是 128×128,隨著手機(jī)的發(fā)展,其分辨率將會越來越高,那么如何編輯更高分辨率的圖像?同時,很多場景對精確度的需求也變得越來越高,比如在 3D 重建中,醫(yī)療領(lǐng)域希望人臉的深度信息精度能夠從 0.1 厘米提升到 0.05 毫米,這樣便可以精準(zhǔn)估計面部運(yùn)動和身份信息。另外,一些特殊應(yīng)用場景會要求生成十幾萬人乃至幾億人的人臉數(shù)據(jù)。另一方面,人臉圖像編輯也是機(jī)器學(xué)習(xí)的重要研究內(nèi)容,它的理論學(xué)習(xí)方法、硬件和軟件都需要更大的突破,才能得到符合人類視覺感知的結(jié)果。

感謝中心成員張堃博、宋凌霄、吳翔、李祎、胡坦浩、黃懷波、李志航、李佩佩、胡一博和宋林森等人對于本次報告給予的協(xié)助和支持。謝謝大家。