 掃一掃
掃一掃
服務(wù)近2000家企業(yè),依托一系列實(shí)踐中打磨過(guò)的技術(shù)和產(chǎn)品,根據(jù)企業(yè)的具體業(yè)務(wù)問(wèn)題和需求,針對(duì)性的提供各行業(yè)大數(shù)據(jù)解決方案。
hadoop2.7.3在centos7上部署安裝(單機(jī)版)
來(lái)源:未知 時(shí)間:2018-28-17 瀏覽次數(shù):342次
hadoop單機(jī)版運(yùn)行環(huán)境搭建,相對(duì)于分布式版本而言單機(jī)版相對(duì)簡(jiǎn)單,適合于初學(xué)者學(xué)習(xí)使用
(1)hadoop2.7.3下載
(1)hadoop2.7.3下載
(前提:先安裝java環(huán)境)
下載地址:http://hadoop.apache.org/releases.html
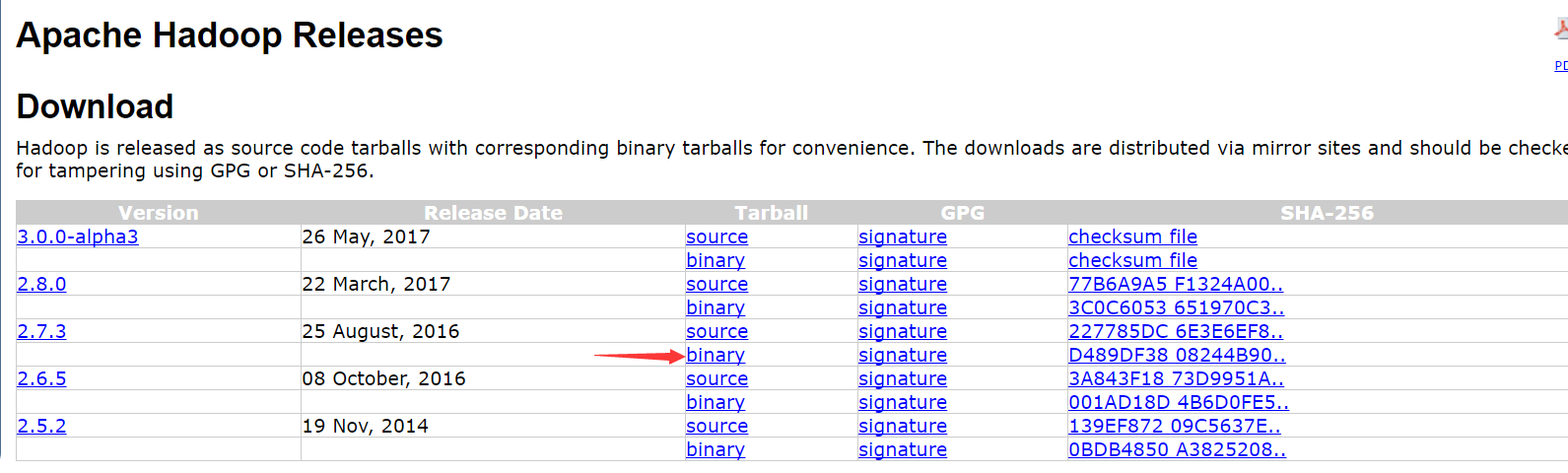
(注意是binary文件,source那個(gè)是源碼)
(2)解壓tar.gz

(3)配置hadoop
1.修改/usr/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh 文件的java環(huán)境,將java安裝路徑加進(jìn)去:
- export JAVA_HOME=/alidata/server/java-1.7.0
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
注意,不加此配置會(huì)導(dǎo)致部分hadoop命令運(yùn)行時(shí)找不到native lib
#export HADOOP_ROOT_LOGGER=DEBUG,console //查看hadoop日志,一般報(bào)錯(cuò)上語(yǔ)句為報(bào)錯(cuò)原因,需要調(diào)試時(shí)開(kāi)啟
配置hadoop環(huán)境變量
vi /etc/profile
- export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
- export PATH=$PATH:$HADOOP_HOME/bin
有的安裝介紹中說(shuō)是vi ~/.bash_profile,其實(shí)也可以用這個(gè),2個(gè)命令在不同系統(tǒng)用戶(hù)的環(huán)境配置的作用域不一樣。參考:
http://blog.csdn.net/caiwenfeng_for_23/article/details/44242961
使之生效:
- source /etc/profile
2.修改/usr/hadoop/hadoop2.7.3/etc/hadoop/core-site.xml 文件,
- <configuration>
- <!-- 指定HDFS老大(namenode)的通信地址 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:9000</value>
- </property>
- <!-- 指定hadoop運(yùn)行時(shí)產(chǎn)生文件的存儲(chǔ)路徑 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/usr/hadoop/tmp</value>
- </property>
- </configuration>
fs.defaultFS直接用localhost就行,如果重命名了主機(jī)名,也可以用重命名的。
3.修改/usr/hadoop/hadoop2.7.3/etc/hadoop/hdfs-site.xml
- <configuration>
- <property>
- <name>dfs.name.dir</name>
- <value>/usr/hadoop/hdfs/name</value>
- <description>namenode上存儲(chǔ)hdfs名字空間元數(shù)據(jù) </description>
- </property>
- <property>
- <name>dfs.data.dir</name>
- <value>/usr/hadoop/hdfs/data</value>
- <description>datanode上數(shù)據(jù)塊的物理存儲(chǔ)位置</description>
- </property>
- <!-- 設(shè)置hdfs副本數(shù)量 -->
- <property>
- <name>dfs.replication</name>
- <value>1</value>
- </property>
- </configuration>
4.SSH免密碼登錄
- ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
- cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- chmod 0600 ~/.ssh/authorized_keys
5.hdfs啟動(dòng)與停止
第一次啟動(dòng)hdfs需要格式化,之后啟動(dòng)就不需要的:
- cd /usr/hadoop/hadoop-2.7.3
- ./bin/hdfs namenode -format
啟動(dòng)命令:
./sbin/start-dfs.sh
停止命令:
- ./sbin/stop-dfs.sh
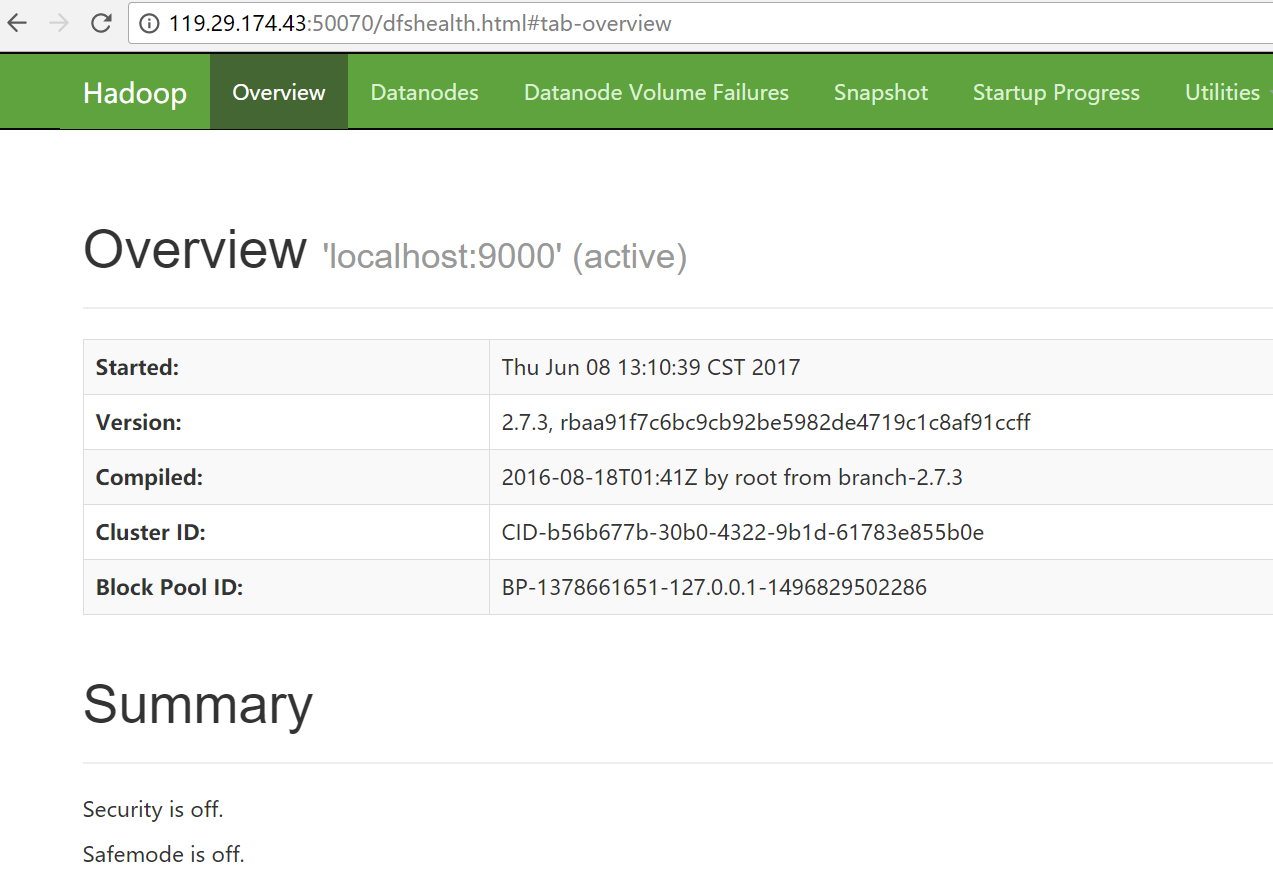
從圖中看,會(huì)啟動(dòng)namenode,datanode,secondarynamenode
瀏覽器輸入:http://119.29.174.43:50070 查看效果:

6.接下來(lái)配置yarn文件. 配置/usr/hadoop/hadoop-2.7.3/etc/hadoop/mapred-site.xml 。這里注意一下,hadoop里面默認(rèn)是mapred-site.xml.template 文件,如果配置yarn,把mapred-site.xml.template 重命名為mapred-site.xml 。如果不啟動(dòng)yarn,把重命名還原。
- mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
- <configuration>
- <!-- 通知框架MR使用YARN -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
7.配置/usr/hadoop/hadoop-2.7.3/etc/hadoop/yarn-site.xml文件,
- <configuration>
- <!-- reducer取數(shù)據(jù)的方式是mapreduce_shuffle -->
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- </configuration>
8.啟動(dòng)yarn
啟動(dòng):
- ./sbin/start-yarn.sh
停止:
./sbin/stop-yarn.sh
如圖:
會(huì)啟動(dòng)resourcemanager,nodemanager
可以用jps命令查看啟動(dòng)了什么進(jìn)程:
瀏覽器輸入:http://119.29.174.43:8088 (8088是默認(rèn)端口,如果端口占用,先把占用的端口殺掉 netstat -ano)